近期,中國公司幻方量化旗下的杭州深度求索人工智能基礎技術研究有限公司(DeepSeek)推出了兩款引人注目的模型:DeepSeek-V3 和 DeepSeek-R1。這些模型以低成本和高效能為特色,對全球科技產業產生了深遠影響。
在 1 月 27 日,科技股市大幅下挫,那斯達克指數下跌 3.1%,標普 500 指數下跌 1.5%,其中 AI 晶片供應商Nvidia(NVDA)股價重挫近 17%,市值單日蒸發約 6000 億美元。市場上開始出現並放大一些問題的聲量:DeepSeek 的低成本模型是否相削弱美國科技巨頭在 AI 賽道上的領先優勢,並對 Nvidia 等算力供應商的真實需求提出質疑。
今天就跟著 fiisual 小編一起來了解 DeepSeek 的技術和成本,以及未來對 AI 產業有著什麼影響吧!
Deepseek 核心技術
多專家機制(Mixture-of-Experts, MoE)
DeepSeek-V3 採用了一種名為 MoE 的架構,針對不同的輸入選擇性地活化部分專家,已提高模型的效率。因此,儘管在 MoE 架構下包含了約 6710 億個參數,但每次推理可能僅會啟用其中的 370 億個參數,約僅有 5%。這種設計大幅降低了計算資源的消耗,同時保持了模型的高效能。
動態知識喚醒
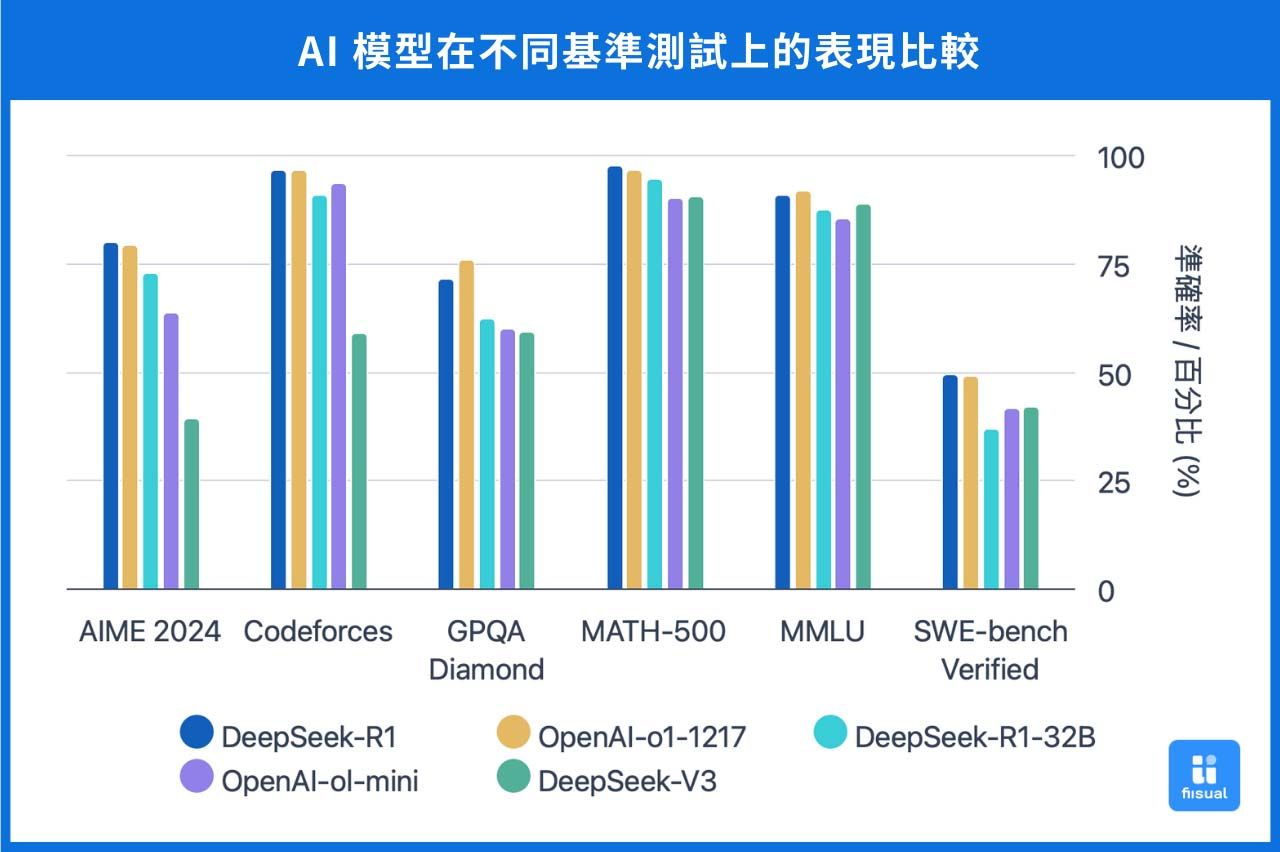
根據現有資料,DeepSeek-V3 在 MMLU(Massive Multitask Language Understanding)基準測試中取得了 87.1% 的準確率,顯著優於前代模型 DeepSeek-V2 的 78.4%,並接近閉源模型 GPT-4o(約87.2%)和 Claude-3.5-Sonnet(88.3%)的水平。其獨創的「動態知識喚醒機制」,能夠透過動態調整模型注意力分佈的方式,根據輸入內容及上下文,自動調用不同的專業知識模組,提高模型的感知力及準確率。例如在處理 AIME 2024 數學競賽題目時,模型會優先啟動數理邏輯專家模組,確保推導過程的嚴謹性。
長文本處理能力
結合分層注意力與語境壓縮技術,V3 在 LongBench v2 測試中,對 10 萬字符長文本的關鍵信息提取準確率達 92.7%,較 GPT-4o 提升 14%。這項突破得益於其創新的記憶單元分區管理系統,能將不同類型的上下文信息(如事實數據、邏輯鏈條、任務指令)進行物理隔離存儲,避免信息干擾。
分層注意力(Hierarchical Attention): 這種機制透過多層次的注意力結構,讓模型能夠在不同的層級上捕捉文本的全局和局部資訊。具體而言,模型首先將文本劃分為較大的區塊,以識別關鍵部分;然後,在這些關鍵區塊內,進行更深入的注意力計算,以提取其中的核心資訊。這種分層處理方式,有助於模型同時掌握全局上下文和細節內容。
語境壓縮(Context Compression): 在處理超長文本時,直接分析整個內容會消耗大量資源。語境壓縮技術透過壓縮記憶機制,將之前的上下文資訊濃縮為精簡的表示,保留關鍵內容,捨棄多餘資訊。這樣,模型在處理新資訊時,可以有效利用壓縮後的記憶,減少計算量,同時保持對長期上下文的理解。
中文語言能力
根據現有資料,DeepSeek-V3 在中文事實性知識測試中展現了不錯的表現。在 C-SimpleQA 基準測試中,DeepSeek-V3 的準確率達到 89.3%,較 Qwen2.5-72B 高出 8%。一成就主要歸功於其針對中文語境開發的語義網格技術,該技術增強了模型對中文成語、方言及專業術語的理解能力,使其達到母語專家的水準。
語義網格: 語義網格是一種技術,將語義技術與網格計算相結合,希望能夠透過語義的描述和關聯標註,實現資源利用的高效。它透過語義標註和本體論等手段,提升資源的可發現性和互操作性,使得資源能夠被更精確地檢索、整合和利用,從而提高計算和資料處理的效率。 DeepSeek 針對了 Hopper 架構的 GPU 進行深度優化,並通過了 NVLink 與 RDMA 的調度工作,在 H800 集群上實現了160GB/s 的節點內帶寬與 50GB/s 的跨節點帶寬。
Deepseek 模型
根據上述的核心技術框架,DeepSeek 近期推出了三款具有代表性的模型,展示了其在人工智慧領域的技術創新:
DeepSeek-V3
DeepSeek-V3 是一款通用模型,採用了「專家混合」(Mixture of Experts,MoE)架構,總參數量達到 6710 億。每個輸入僅激活 370 億參數,實現高效推理和運算能力。此外,該模型引入了多頭潛在注意力(Multi-head Latent Attention,MLA)技術,通過低秩聯合壓縮,減少鍵值(KV)快取需求,提升推理效率。
DeepSeek-R1-Zero
DeepSeek-R1-Zero 是首個完全通過強化學習(Reinforcement Learning,RL)訓練的基礎推理模型,無需監督式微調(Supervised Fine-Tuning,SFT)標記資料。該模型具備自我驗證和反思等特性,展示了以 RL 為核心的推理 AI 發展潛力。然而,由於缺乏 SFT,R1-Zero 的輸出可能存在可讀性差、語言混亂等問題。
DeepSeek-R1
為解決R1-Zero的不足,DeepSeek-R1 在其基礎上引入了少量標記資料和多階段的強化學習流程。首先,使用少量高品質的思維鏈資料對模型進行微調,然後進行兩階段強化學習,以提高輸出內容的可讀性和一致性。DeepSeek-R1 在多項測試中表現出色,其推理能力可與 OpenAI 的 o1 模型相媲美。
這些模型的推出,展示了DeepSeek在降低成本的同時,提升 AI 模型效能的技術實力,對 AI 產業格局產生了深遠影響。
技術成本分析
DeepSeek 因較先進的 H100 晶片遭到美國的出口管制,聲稱其 V3 模型僅使用較舊的 H800晶片 (相近的運算效能,但網路頻寬較低),總訓練成本僅為 557.6 萬美元,對比 Meta 的 Llama 模型、Anthropic 的 Claude 模型,成本都為其十倍以上。
| 品牌 | 模型 | 成本 |
|---|---|---|
| DeepSeek | DeepSeek-V3 | 557.6萬美元 |
| Meta | Llama3.1-405B | 9252萬美元 |
| ChatGPT | GPT-4 | 7087.5萬美元 |
然而,DeepSeek-V3 模型在許多問題的回答方式與 ChatGPT 有相當高的相似度,引發市場對DeepSeek 是否在預訓練 (Pre-tra ining) 階段中,透過知識蒸餾 (Knowledge Distillation) 技術,使用 OpenAI 模型作為教師模型 (Teacher Model) 以提升 DeepSeek 模型推理能力的討論。
知識蒸餾(Knowledge Distillation): 知識蒸餾是一種機器學習技術,用來把大模型的知識「壓縮」到一個小模型裡,讓它變得更輕量、運行更快,但仍然能保持接近大模型的效果。
我們可以把大模型想像成一個老師,而小模型就是學生。當一名優秀的老師能夠清楚地將核心概念教給學生時,學生便能減少在學習上所需要耗費的資源,並盡量達到老師的水準。
OpenAI 的高級顧問 David Sacks 曾表示,DeepSeek 可能複製了 ChatGPT 的技術。另外也曾有內部人士透露,OpenAI 內部有證據顯示,一些中國的公司試圖透過蒸餾的方式達到複製模型的效果,這可能違反了 OpenAI 的服務條款。
影響分析
AI 硬體設備
DeepSeek 的出現不僅使蒸餾技術在 AI 模型開發中獲得更多關注,提升了以小型模型提供高效能的可行性,同時也引發了市場對 AI 硬體需求的重新評估。
短期來看,由於 DeepSeek 採用如 H800 等較低成本硬體並透過技術創新降低算力需求,市場對高階 GPU(如 H100)的需求期待可能出現鬆動,這也是 Nvidia 的股價在消息公布後出現下跌的主因。
然而,有些專家持樂觀態度,認為技術創新降低了 AI 模型的運算成本並提升效率,這將激發更多應用場景和需求,進而推動 AI 硬體需求的增長,就如同傑文斯悖論(Jevons Paradox)所描述下技術成長和資源再投入的關係。因此,硬體供應商的長期需求曲線可能持續上升,AI 生態系統的規模也有望不斷擴大。
傑文斯悖論(Jevons Paradox): 經濟學理論,指的是當技術進步提高了資源使用效率時,反而可能導致該資源的總消耗量增加。原因是因為資源效率的使用提升後,會降低單位使用成本,進而刺激更多的需求,使得資源消耗反而超過原水平。
英國經濟學家威廉・傑文斯(William Jevons)在其著作《煤炭問題》中提出了他對於蒸汽機技術的觀察。他觀察到雖然瓦特改良了蒸汽機的技術並大幅提升其使用效率,但英國的煤炭消耗量卻隨之大幅增加。
市場態度
AI巨頭表態
OpenAI
OpenAI 在 1/31 發布 o3-mini 模型,市場解讀頗有為抗衡 DeepSeek-R1 的推理模型的意味。同時,部分公司內部人士也指控 DeepSeek 侵權,然而 OpenAI 執行長 Sam Altman 在近期表示,公司目前「沒有計畫」對 DeepSeek 在內的中國 AI 新創公司提起訴訟。他強調,OpenAI 的重心仍然放在打造優質產品,並透過技術實力維持業界領先地位。
Anthropic
Anthropic 執行長 Dario Amodei 表示:「DeepSeek 生產的模型性能接近 7-10 個月前的美國模型,但成本更低,且成本降低為可預期的,只是第一個展示的是中國公司。」他認為 DeepSeek 仍不足以構成威脅,市場上的擔憂過大,但同時也呼籲應嚴格執行晶片出口管制,將美國暫時的領先轉化為持久的優勢。
想看更多AI 相關的文章嗎? 新聞專題:OpenAI 最新產品更新
