商業模式介紹
NVIDIA 作為全球領先的 GPU 供應商,其成功來自於獨特且完善的商業模式,核心在於完整的生態系統(Ecosystem)與有效的商業槓桿(Leverage)。
生態系統(Ecosystem)
NVIDIA 的生態系統是公司競爭力的核心基礎之一。透過其自主開發的 CUDA(Compute Unified Device Architecture)平台,NVIDIA 建立了龐大且完善的軟硬體整合生態圈。
什麼是 CUDA? CUDA(Compute Unified Device Architecture)是一種軟硬體整合技術,允許開發者利用 NVIDIA 的 GPU 進行圖像處理以外的運算。NVIDIA 的生態系統以其自主開發的 CUDA 平台為核心,企圖打造軟硬體結合的完整生態圈。
以 CUDA 平台為核心,NVIDIA 也推出了多項先進技術和平台,試圖將不同開發領域納入生態系中,打造產品護城河。我們這裡舉出 NVIDIA 近期重視的幾個技術和平台:
NVIDIA Drive
NVIDIA DRIVE 是自動駕駛領域的端到端平台,整合嵌入式超級計算硬體與軟體開發工具,為車輛提供先進的人工智慧功能。該平台能即時處理來自攝像頭、雷達和激光雷達等各種傳感器的數據,實現安全可靠的自動駕駛功能。
在硬體組成方面,NVIDIA 提供的 DRIVE Hyperion 是一套完整的自動駕駛參考架構,整合了包括 DRIVE AGX 系列在內的車載運算系統與各類感測設備。此外,最新推出的 DRIVE Thor 作為 AGX 系列的最新系統晶片(SoC),基於先進的 NVIDIA Blackwell 架構打造,並首次引入推理 Transformer 引擎,進一步強化平台的運算性能與穩定性。作為 DRIVE AGX Orin 的升級產品,DRIVE Thor 展現出顯著提升的效能與技術優勢。
NVIDIA DRIVE 平台已被多家全球領先的汽車製造商和技術公司採用,以推動自動駕駛技術的發展。目前已知有包括 Mercedes-Benz、Jaguar Land Rover、Volvo Cars、現代汽車、比亞迪、Polestar及蔚來等知名合作廠商。
NVIDIA DLSS
NVIDIA DLSS(Deep Learning Super Sampling)技術,協助遊戲開發者透過人工智慧提升遊戲畫質與運行流暢度,明顯改善使用者的視覺體驗。
該技術已獲得多家知名遊戲開發廠商的支持與採用,包括 Epic Games、CD Projekt Red、Activision 等。同時,NVIDIA 亦透過經銷商如華碩、技嘉、微星等積極推廣 GeForce GPU,以進一步提升遊戲效能並拓展市場影響力。
NVIDIA Jetson
NVIDIA Jetson 是專為自主機器領域設計的嵌入式系統,為開發者提供卓越的 AI 計算效能。目前已廣泛應用於機器人、無人機、自動導引車輛(AGV)、智慧零售、智慧城市監控、工業自動化、智慧醫療設備等多種自動化及智慧型設備領域。
實際應用案例包括新漢科技推出的邊緣 AI 交通電腦、研揚科技的智慧視覺辨識系統,以及立普思科技(LIPS)與 Jetson 平台整合的 3D 相機解決方案。
NVIDIA Maxine
NVIDIA Maxine 為一套 AI 軟體開發工具包,提供視頻降噪、虛擬背景替換、面部表情重建等先進功能,旨在提升視頻通訊的品質與互動體驗。
目前已有多家企業採用 NVIDIA Maxine,包括騰訊雲利用其 AI 綠幕功能強化雲端視頻服務、Looking Glass 公司將 Maxine 3D 技術融入全息視頻會議應用,以及 Pexip 透過 Maxine 的音頻降噪技術提升視頻通訊品質,充分展現出 Maxine 技術的實際價值與多樣化應用潛力。
NVIDIA Omniverse
NVIDIA Omniverse 是一個即時 3D 設計協作與模擬平台,透過整合多種不同軟體工具和工作流程,協助設計師、工程師和內容創作者進行跨平台的協同合作與創作。
目前已知的實際應用有包括 BMW 集團採用 Omniverse 平台所打造的數位孿生工廠,大幅優化汽車生產與設計流程,以及知名動畫公司皮克斯(Pixar)也選用 Omniverse 加速動畫設計與內容製作流程。此外,亞馬遜(Amazon Robotics)也透過 Omniverse 模擬並渲染虛擬的 3D 環境,試圖優化倉儲物流機器人的工作流程。
NVIDIA CUDA Quantum
NVIDIA CUDA Quantum 是一個開放原始碼平台,旨在將量子運算與經典運算相結合。該平台提供高效能的開發環境,使研究人員和開發者能夠設計、模擬及執行量子演算法,並有效整合現有的 CPU 與 GPU 資源,加速量子科技的研究與應用。此外,NVIDIA Quantum Cloud 則為用戶提供強大的雲端量子運算服務。
目前已有多個知名機構與 NVIDIA 合作推進 CUDA Quantum 的實際應用,包括量子技術公司 Xanadu、量子計算服務商 Pasqal,以及量子算法開發商 Classiq。
 資料來源: NVIDIA Keynote at COMPUTEX 2023直播
資料來源: NVIDIA Keynote at COMPUTEX 2023直播
推廣開源生態圈
NVIDIA 也積極透過開放合作與平台生態圈推廣,透過與全球軟硬體企業建立廣泛的技術合作,迅速切入不同的垂直市場,將核心技術有效落地於實際產品和解決方案中。這也有效地讓 NVIDIA 可以快速的適應 AI 浪潮下產品的快速變動。
- 與 AWS、Google、Microsoft 等科技巨頭合作,共同推動雲端 AI 服務。
- 與學術界及研究機構合作,共同培養新一代技術人才,進一步擴大生態圈的影響力。(成立深度學習學院 DLI)
這種全面的生態系統策略,不僅有效降低客戶轉換成本(Switching Cost),更提高了客戶的忠誠度,形成競爭壁壘,進而鞏固 NVIDIA 的市場領導地位。
商業槓桿(Leverage)
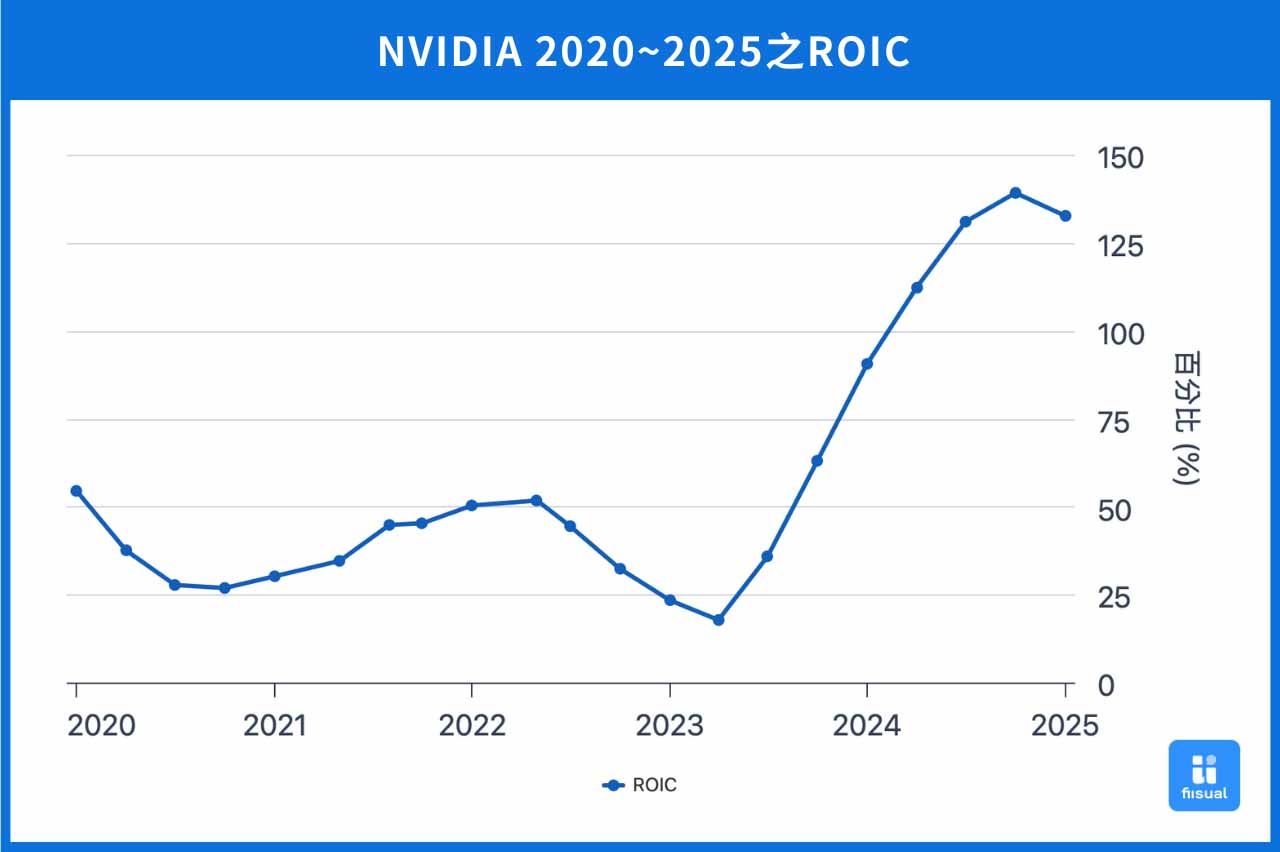
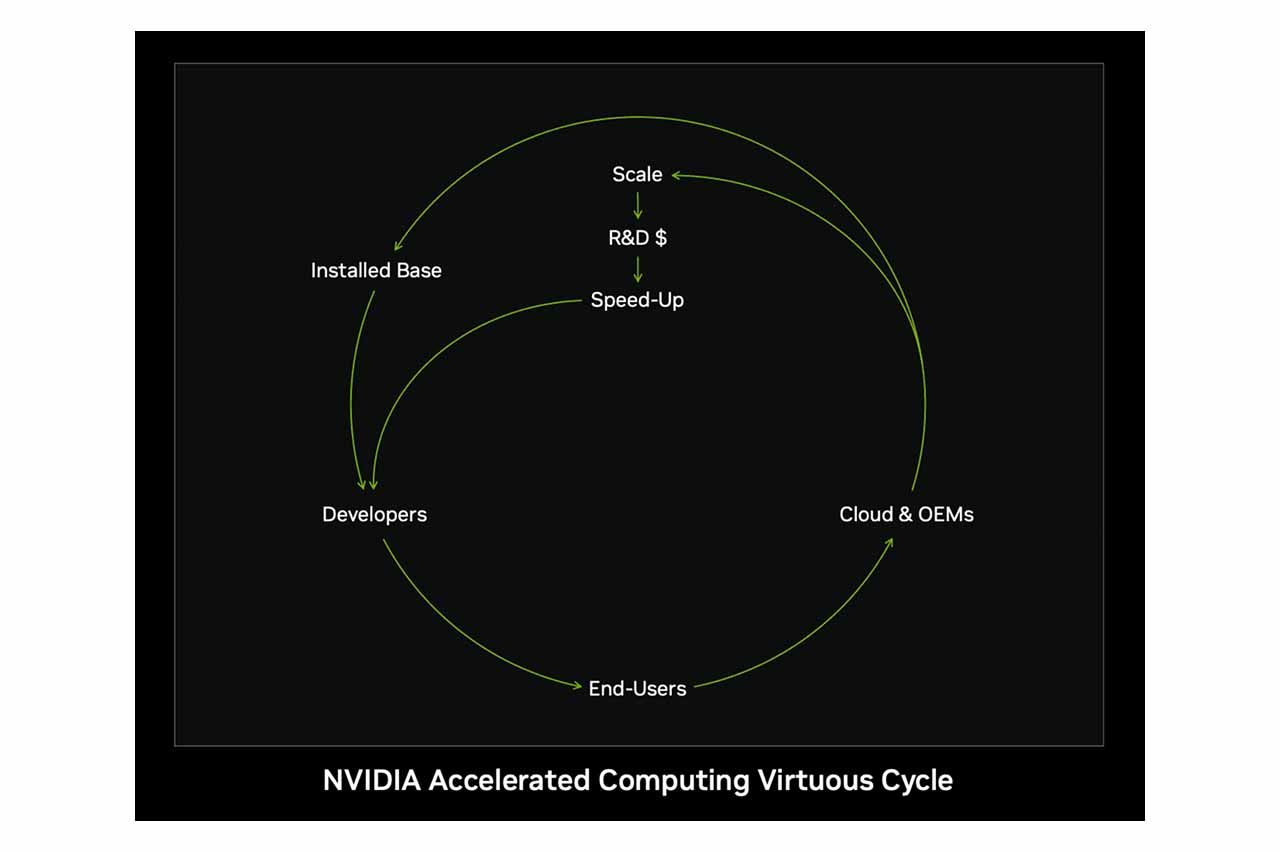
NVIDIA 的商業槓桿策略主要展現在其核心技術具備跨市場重複應用的能力,藉由單一技術架構支援多個垂直市場,達到規模經濟效應。例如,以 GPU 為核心的技術架構,不僅廣泛應用於遊戲市場,亦能延伸至人工智慧(AI)計算、自動駕駛技術、虛擬實境(VR)及資料中心等多元領域。這種跨市場重複運用的策略,使 NVIDIA 能有效提高產品開發的投入資本報酬率(ROIC),降低各市場進入時的風險,並透過研發成本的分攤,進一步降低產品的單位成本,增強企業競爭優勢。
具體而言:
- GeForce 系列專注於遊戲市場。
- Quadro 系列專注於專業圖形與辦公應用。
- Iray 系列則應用於虛擬實境(VR)。
- DRIVE 系列聚焦於自動駕駛。
- Hopper 和 Blackwell 系列則用於數據中心與高效能 AI 運算。

透過這種技術槓桿模式,NVIDIA 得以迅速切入新興市場,擴展收入來源。例如:
- 原先專為遊戲設計的 GeForce GPU 架構經過調整與優化後,成功跨足 AI 計算(如 Tesla、Blackwell 系列)與汽車自動駕駛市場(如 Drive 系列)。
- 利用 GPU 強大的平行運算能力,在深度學習市場興起後,迅速成為全球 AI 運算領域的主要解決方案提供商。
綜合以上,NVIDIA 透過完整的生態系統與有效的商業槓桿模式,不斷強化自身競爭力並創造長期價值。未來,隨著 AI 與自動駕駛的普及,這一模式將持續帶來巨大的成效,使 NVIDIA 進一步提升市場影響力與競爭優勢。
產品線介紹及佈局
NVIDIA透過多元化的產品線布局,以滿足不同市場需求,產品線主要涵蓋遊戲、人工智慧及資料中心、自動駕駛等領域。
遊戲用 GPU:GeForce 系列

GeForce 系列是 NVIDIA 專為遊戲玩家打造的 GPU 產品,以卓越的圖形渲染能力與高效能運算表現,提升遊戲的流暢性和視覺效果。例如最新的 GeForce RTX 5090、5080、5070 等 GPU,均搭載最新的 Blackwell 架構,具備先進的光線追蹤技術(Ray Tracing)與 DLSS 4 技術,大幅提升遊戲畫面的逼真度與效能,廣泛應用於 AAA 級遊戲及高解析度遊戲需求。
AI 應用 GPU:Hopper & Blackwell
Hopper 系列

Hopper 架構專為高效能 AI運算 設計,應用於深度學習訓練、HPC(高效能計算)與企業 AI 推理。旗艦產品 H200 GPU 搭載 Transformer Engine,顯著提升 AI 訓練與推理效率,特別適用於 GPT、BERT 等 AI 模型。Hopper 仍為 HPC 與雲端 AI 推理的主流選擇,但隨著 Blackwell 架構 推出,市場需求逐步轉向更高效能解決方案。
Hopper 架構特色
- 第一代 Transformer Engine:加速 AI 訓練與推理,特別針對大型語言模型(LLM)。
- 第四代 NVLink:提升 GPU 之間的連結速度, 支持超大規模 AI 計算。
- HBM3e 記憶體:支援更高頻寬和更低功耗的高效能 AI 運算。
應用場景
- 超級計算機(HPC):科學研究、醫學影像分析。
- 資料中心 AI 計算:雲端 AI 服務、AI 模型訓練與推理。
- 企業 AI 解決方案:自動語音識別、影像分析等。
Hopper 架構雖然仍在市場上佔據重要地位,但隨著 Blackwell 架構(B200、GB200) 的推出,H200 的需求逐漸轉向較成熟的 AI 計算與資料中心應用。
Blackwell 系列
Blackwell 架構是 NVIDIA 最新 AI GPU 技術,專為 生成式 AI、大型語言模型(LLM)與超大規模 AI 計算設計。B200 GPU 相較 H100 能效提升 2.5 倍,並支援 HBM3e 記憶體、NVLink 5.0,進一步降低 AI 計算能耗與成本。此外,GB200 超級晶片整合 B200 GPU + Grace CPU,提升 AI 訓練與推理解決方案,適用於 Google、Meta、OpenAI 等企業的大型 AI 模型訓練。
Blackwell 架構的核心產品
1. B200 GPU
- 採用 台積電 4NP 製程,內含 2080 億個電晶體,專為 NVIDIA 高效運算需求量身打造。
- 第二代 Transformer Engine,強化 大型語言模型(LLM)與專家混合(MoE)模型 的訓練與推理。
- 內建 解壓縮引擎,可透過高速 NVLink 連結 NVIDIA Grace CPU,共享高達 900 GB/s 雙向頻寬記憶體,加速 AI 運算與資料處理。
2. GB200 AI 超級晶片
- 由兩顆 B200 GPU + Grace CPU 組成,可進一步提升 AI 運算效率。
- 提供 NVL36 和 NVL72 兩個版本,提高 GPU 之間的數據傳輸效率,降低延遲。
- 針對超大規模 AI 模型訓練(如 GPT-4、Gemini 1.5) 進行優化。
Blackwell 市場趨勢與影響
- 市場需求旺盛:Blackwell GPU 在 超大規模 AI 計算 領域備受青睞,Google、Microsoft、Meta、OpenAI 等企業均已部署。
- 逐步取代 Hopper:Blackwell 成為新一代 AI 運算核心,但 H200 仍廣泛應用於成熟 AI 計算與 HPC 領域。
- 短期毛利率下降:由於 Blackwell 初期生產成本較高,NVIDIA 毛利率從 75% 降至 73.4%(2025 Q4),但隨量產提升,毛利率有望回升。
- 成長潛力強勁:隨 AI 應用需求持續上升,Blackwell 產品線預計將進一步推動 NVIDIA 資料中心營收增長。
以下是 Hopper 架構(H200)和 Blackwell 架構(GB 200)的比較表格。
| Hopper 架構 (H200) | Blackwell 架構 (GB200) | |
|---|---|---|
| 晶片製成 | TSMC 4N | TSMC 4NP 客製化 |
| 目標&應用 | 數據中心&AI 訓練 | 生成式 AI&即時推理 |
| 記憶體 | 141 GB HBM3e,4.8 TB/s 帶寬 | 13.5 TB HBM3e,576 TB/s 帶寬 |
| Transformer Engine | 第一代 | 第二代,針對生成式 AI 和 LLM 推理優化 |
| 互聯技術 | 第 4 代 NVLink,600 GB/s | 第 5 代 NVLink,1.8 TB/s |
| 效能提升 | 相比 H100 提升約 1.9 倍 | 相比 H100 提升高達 30 倍(推理性能) |
| 能耗管理 | 最大 TDP 700W | 最大 TDP 1200W(NVL72 配置) |
| 超級晶片 | 無 | GB200(B200 GPU + Grace CPU) |
| 適用場景 | HPC、資料中心、企業級 AI | 生成式 AI、大型LLM、超大規模 AI |
產品競爭優勢
市占率遠超同行,生態系是關鍵
 輝達資料中心 GPU 市占率高達 92%,相當驚人。
輝達資料中心 GPU 市占率高達 92%,相當驚人。
隨著 AI 發展加快,晶片需求也日益增長當中。GTC 大會上,黃仁勳表示美國四大 CSP 廠於去年購買了 130 萬個 Hopper 架構晶片,又於今年購買了 360 萬個 Blackwell 架構晶片,顯示下游算力囤積量驚人。而根據 IoT Analytics 的市場份額調查,截至 2025 年 3 月,輝達於資料中心 GPU 全年市占率高達 92%,而第二大的 AMD 僅占據4%,輝達在資料中心 GPU 市場中獨佔鰲頭。
輝達之所以能達到如今地位,很大一部分歸功於旗下強大的 CUDA 平台。CUDA(Compute Unified Device Architecture)首次於 2006 年推出,作為一個運算平台與程式設計模型,其成功實現 GPU 從圖形渲染到通用計算的創新突破。開發人員得以運用工具如:C、C++等,編寫程式碼將較複雜、大量的計算需求透過 CUDA 轉交 GPU 執行,使 CPU 與 GPU 可以發揮各自優勢,有效分工。隨著 AI 爆炸式的發展,晶片承載的計算量日益增加,CUDA 給予使用者最大的調整彈性 ,成為 GPU 得以在不同領域計算發揮最大效能的關鍵。由於 CUDA 只供給輝達自家的晶片運行,方便的功能與多年的耕耘亦累積了不少忠實用戶,建構輝達現今的核心護城河。
技術與算力為當前頂尖
目前市場上第二大的半導體公司為 AMD,而多年的對手 Intel 也正積極拓展資料中心 GPU 市場當中。以下為輝達與市面上其他的晶片比較:
| GB200 | MI 300x | Guadi 3 | |
|---|---|---|---|
| 公司 | NVIDIA | AMD | Intel |
| 構造 | 由一顆 Grace CPU 與 兩顆Blackwell GPU 構成 | 融合 CPU 與 GPU 於同一處理器,採用 CDNA 3 架構 | 異質電腦架構,並非 CPU 及 GPU 的集成,但仍專注於計算 |
| 算力 | 高 | 中 | 低 |
| 預估價格(美元) | 60,000 - 70,000 | 14,813 | 15,650 |
| 性價比 | 低 | 高 | 中 |
| 其他優勢 | CUDA 整合平台,專為 AI 與高效能運算設計 | 性價比最高,得與輝達 Hopper 系列競爭 | 在成本控制上有明顯優勢 |
雖然價格不及同行實惠,但在算力與技術上輝達遠超同行,再加上先前提到的護城河 CUDA,於目前算力軍備競賽中,業界主要仍向輝達購買。儘管如此,AMD MI 300 系列仍是值得關注的競爭對手,因其性價比相當優越。在 2024 年 6 月的台北國際電腦展上,執行長蘇姿丰表示,2025 年將推出的 MI 325x,其記憶體容量為輝達 H200 的 1.8倍、記憶體頻寬為 1.3 倍,並在 FP8 及 FP16 數據格式的算力超越 H200 1.3倍。未來也預計推出 MI 350、MI 400 等,有機會於往後以更實惠的價格及更強大的計算能力打敗輝達 Hopper 系列。另外,超微旗下的 ROCm 則為開源計算平台,相對於封閉的 CUDA,ROCm 兼容旗下與其他廠商硬體開發,提供更大的靈活性。
另外,ASIC 晶片(Application-Specific Integrated Circuit)的興起也是另一威脅。ASIC 為客製化專用晶片,下游客戶多直接與 IC 設計大廠如:博通(BroadCom)等合作研發,根據自身需求創造最符合效益的晶片。ASIC 的最大優勢在於高度優化的資源分配,實現功耗下降、成本控制的效果。若要發展通用計算,最終仍需依賴大廠所生產的通用晶片,但 ASIC 為市場帶來了另一種可行的選擇,未來兩者可能共同佔據市場,相輔相成。
長遠而言,待資料中心市場發展更加成熟後,CSP 廠可能會更講求成本控制,屆時「性價比」將成為重要關鍵,可觀察輝達的策略調整。
產品更新:GTC 大會
Blackwell Ultra 與 Feynman 推出,迭代快速
3 月 19 日凌晨,黃仁勳於輝達 GTC 大會上揭示最新 Blackwell Ultra 晶片,其主要為推理 AI 及代理 AI 所設計,性能為當前 Blackwell 晶片的 1.5 倍,預計於下半年上市。另外,下一代 Rubin 架構晶片將於 2026 推出,其中新一代的 Vera CPU 為當前 Grace CPU 的兩倍。最後,他也驚喜宣布輝達將於 2028 年推出全新的 GPU 架構-Feynman。

除此之外,黃仁勳也一併發表了針對 AI 推理的開源模型 Dynamo,得以快速擴展 AI 的推理能力並降低成本。輝達 GPU 的迭代速度遠超同行,強大的研發能力與技術也助益客戶在軟硬體的應用上發揮更大效益,成為領先市場的一大優勢。
GB300 最新進度
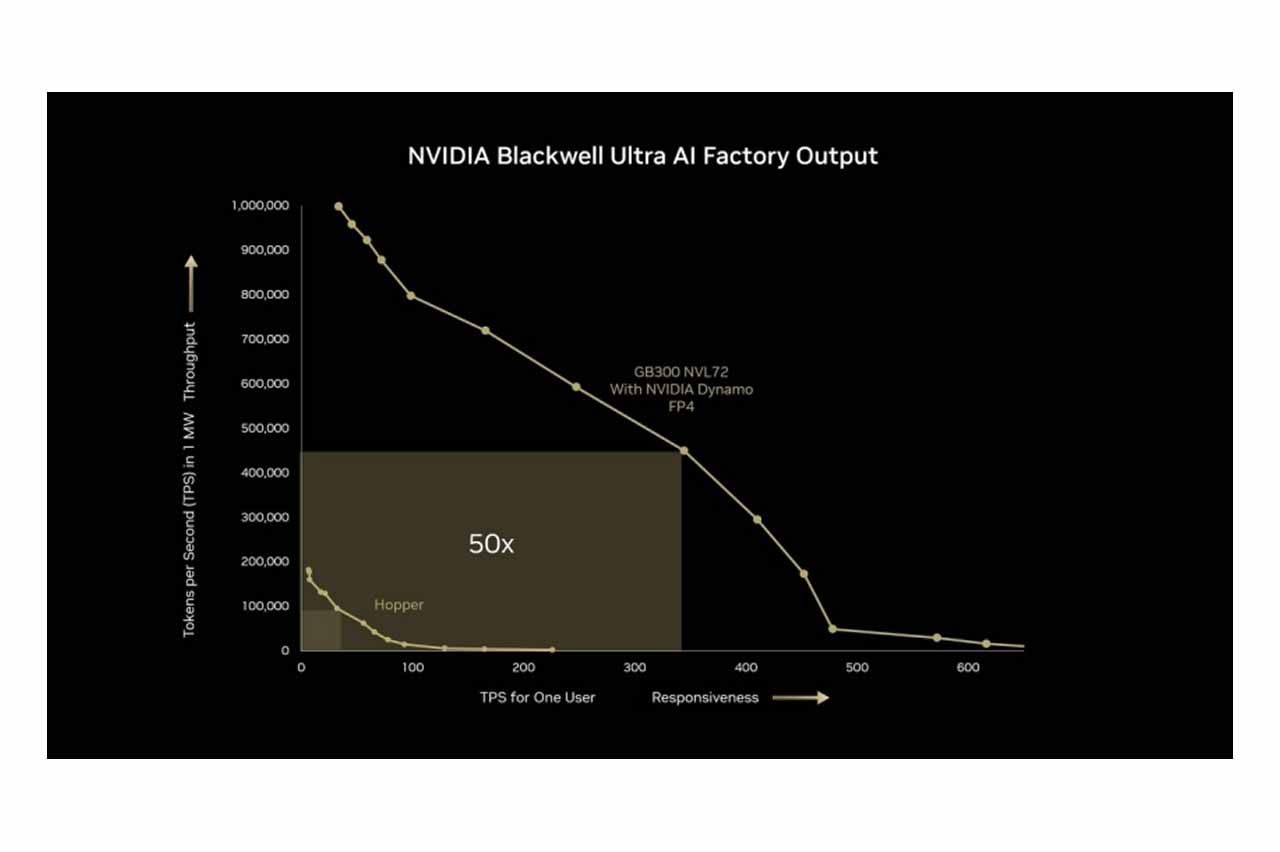
NVIDIA 預計於 2025 年下半年推出 Blackwell Ultra NVL72(GB300)機櫃平台。該產品將採用 SXM7 與 Cordelia 模組設計,取代原本的 Bianca 主板,每個 Cordelia 模組整合 4 個 Blackwell B300 GPU 及 2 個 Grace CPU(共計 72 GPU、36 CPU),精簡運算托盤結構並降低空間需求,提供 OEM 和 ODM 更高的整合彈性。此平台能將 AI 推理效能顯著提升,用戶響應速度提高 10 倍,吞吐量提升 5 倍,整體產出效能達 50 倍提升。
結論
現今,不論是資料中心或遊戲領域,輝達在 GPU 市場中扮演舉足輕重的角色,短期內同行難以望其項背。然而,隨著技術日新月異、市場逐漸成熟,未來競爭將轉移至算力成本的控制上,「性價比」為重要關鍵。如何活用生態圈優勢留住用戶而不被開源平台取代,以及價格上能否持續下修將成為輝達未來的兩大挑戰,而其技術演進是整個 GPU 重要的領先指標。
作為新興發展的產業,AI 終端需求不確定性仍高,輝達的增長力道最終仍取決於終端應用是否能保持強勁。近年來,輝達也積極拓展如:自駕車、機器人等領域,透過持續不斷向世界建構 AI 應用藍圖與想像,輝達得以保持終端需求無虞。對此,建議投資人應密切注意實際需求變化,以免陷入 AI 泡沫的陷阱。
