隨著 AI 模型發展重心由訓練逐步轉向推論,GPU 與 ASIC 晶片的功耗、封裝尺寸與熱密度同步攀升,帶動晶片 TDP 持續上行。若熱能無法即時有效導出,將可能導致伺服器頻繁發生跳機、降頻,甚至影響整體系統穩定性。以 NVIDIA 為例,單顆 B300 晶片 TDP 已達 1,400W,預計於 2026 年下半年推出的 Rubin 將進一步提升至 2,300W,而 2027 年推出的 Rubin Ultra 單顆晶片 TDP 甚至可能突破 3,000W。在此趨勢下,GPU 伺服器散熱架構正由傳統氣冷加速轉向直接液冷方案,後者亦成為當前散熱產業最具成長性的核心方向。
技術背景:散熱技術提升但仍不足
NVIDIA GPU Package、 伺服器機櫃之 TDP 及散熱方案
| 架構 | Ampere | Hopper | Blackwell | Blackwell Ultra | Rubin | Rubin Ultra | Feynman |
|---|---|---|---|---|---|---|---|
| TDP | 400W | 700W | 1200W | 1400W | 2300W | 3000W+ | 4000W+ |
| 散熱方案 | Air-Cooling | Air-Cooling | DLC | DLC | DLC | DLC | Immersion Cooling |
| 導入時間 | 2020 | 2022 | 2024 | 2025 下半年 | 2026 下半年 | 2027 下半年 | 2028 |
| 代表產品 | A100 | H100/H200 | B200/GB200 | B300 | Rubin GPU | Rubin Ultra | Feynman GPU |
| 機櫃架構 | GB200 NVL72 | GB300 NVL72 | VR200 NVL144 | ||||
| 單櫃 TDP | 120-130kW | 130-140kW | <225KW | ||||
| 散熱方案 | Liquid(85%)+Air(15%) | Liquid(85%)+Air(15%) | Liquid(100%) |
傳統氣冷轉向水冷板仍難以滿足高功耗晶片散熱需求
傳統氣冷方案透過風扇與導風道帶走熱能,結構簡便且成本相對低廉,但散熱能力受限於風扇風量與鰭片面積,這導致氣冷在高功率密度運算環境中的散熱效率明顯受限,因此氣冷主要適用於低至中等功率伺服器,難以支援超過約 1,000W 的 TDP。
為改善氣冷散熱能力但仍保留既有設計,業界衍伸出了「水對氣散熱方案」,此方案通常透過液體輔助空氣冷卻,熱傳路徑通常為晶片熱量先由散熱鰭片傳遞至空氣,再由水冷熱交換器將空氣中的熱量帶入水循環系統並排至資料中心外部,由於水在系統中承擔主要的熱量搬運功能,因此整體散熱能力顯著提升,使其可支援約 850–1,200W TDP,水對氣方案最大的優勢在於與既有伺服器架構高度相容,且仍然採用傳統氣冷散熱器與風扇,因此資料中心不需大幅修改伺服器硬體設計即可提高散熱能力,這使其成為 AI 資料中心初期升級的重要過渡方案。然而,此技術的根本限制在於熱傳導路徑中仍包含空氣介質,使其在高功耗環境下仍容易受到氣流效率與局部熱點問題限制,因此 L2A 普遍被視為一種過渡方案,因其無法支援 TDP 超過 1,200W 的 Al 伺服器。
目前主流的「水對水散熱方案」移除機櫃內部的風扇構造,冷卻液透過冷板(cold plate)直接接觸晶片封裝,晶片產生的熱量經由導熱介面材料(TIM)傳導至冷板,再由冷卻液帶走並送至冷卻分配單元(CDU)與資料中心水系統進行熱交換,使熱量大部分保留在液體迴路中,顯著降低對機架的熱負載。 雖然熱導率高於氣冷方案,但液冷板通常在散熱板底部或片側佈置管路,熱能的傳導仍需經過均熱板、TIM 等多個介面,熱阻鏈較長,當 GPU 功耗進一步攀升至約 2000W 以上時,介面熱阻將成為散熱瓶頸, 傳統單相水冷板將逼近極限。
| 技術細分 | 一般氣冷 | 水對氣 | 水對水 |
|---|---|---|---|
| TDP | 500–1000W | 850–1200W | 1200–1500W |
| PUE | 1.5–1.7 | 1.07–1.3 | 1.07–1.3 |
| 優點 | 成本低、技術成熟、維護簡單 | 混合冷卻、可靠度高 | 高散熱效率,適合高熱密度 |
| 缺點 | 無法支援高功耗、噪音污染 | 成本較高、需專業維護 | 初期建置成本高、需 Facility Loop 改造 |
| 預期商用時間 | 已成熟,逐步被水冷取代 | 2024A–2027F 成長期 | 2025E–2030F 主流 |
| 終端應用舉例 | AMD EPYC Genoa / Bergamo、NVIDIA A100 PCIe | 高效能伺服器、部分 AI 應用 | NVIDIA DGX H100 / GB200 NVL72 |
微通道液冷板(MCCP)技術介紹
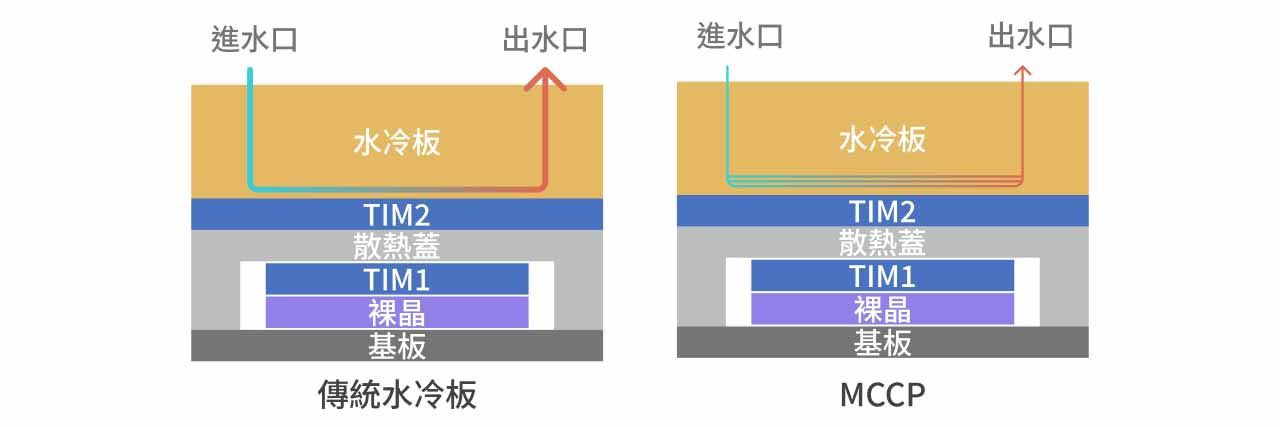
由於傳統水冷板逐步逼近散熱物理極限,業界開始導入 MCCP(Micro Channel Cold Plate)作為改良方案。 兩者在整體封裝架構上大致相同,皆維持 TIM 1、Heat Spreader、TIM 2 與 Cold Plate 的四層結構,差異主要在於 Cold Plate 內部流道設計的進一步優化。
傳統 Cold Plate 的內部水道採宏觀通道設計,通道寬度約 150 μm,冷卻液與金屬壁面的接觸面積有限,換熱效率受制於流體對流邊界層,在 AI 晶片功耗持續攀升的趨勢下逐漸力不從心。MCCP 的改良邏輯直接且精準:在不動封裝架構的前提下,將 Cold Plate 內部通道縮窄至 80–100 μm,通道數量對應增加,冷卻液與金屬壁面的總接觸面積大幅提升,換熱效率因此提高約 1 倍,可應對 Vera Rubin R100 約 1.8 kW 的功耗需求。
MCCP 之所以能幅提升換熱效率,關鍵在於其內部的微流體工程設計。 若我們將微通道水冷板進行內部透視,便能窺見其核心的熱力學引擎。冷卻液從 Inlet 注入蓋板後,並非單純流過一個空腔,而是被強制導流進入由高精度金屬加工所打造的微通道中。
整個散熱載體建立於具備極佳熱傳導率的金屬底之上,其底部緊密貼附於下方之發熱源。在底板上方,工程人員透過極高精度的機械加工技術,建構出密集且平行的散熱鰭片。這些相鄰鰭片之間所形成的微小狹長空間,即為冷卻液流竄的微流道。
在流體動力運作機制上,冷卻液流由模組一端注入,沿著平行的流動方向快速穿梭於微通道陣列中。由於微型鰭片的設計將金屬與液體的接觸表面積較大,冷卻液得以透過高效的強制對流,將底板傳導上來的巨量晶片廢熱迅速帶走。
微通道蓋板(MCL)技術介紹
MCCP 可支撐目前需求,業界加速研發 MCL 以因應更高功耗挑戰
MCCP 的核心價值在於以最小的架構改動換取最快的導入速度,是散熱產業在 MCL 量產就緒之前的關鍵過渡方案。 然而 TIM 2 導熱係數僅 2–7 W/m·K、佔整體熱阻 70% 以上的根本瓶頸並未被解決,面對 2027 年後 AI 晶片突破 2,000W 甚至 3,000W 的功耗預期,MCCP 的改良空間已趨近上限。
| 散熱層級與材料類型 | 熱傳導率 (W/m·K) | 物理特性與影響 | 應用情境與痛點 |
|---|---|---|---|
| 矽晶片(SoC, HBM) | 130 - 150 | 單晶結構,聲子傳導極佳 | 高功率下產生極端熱點 |
| TIM1(液態金屬、銀膠) | 40 - 80 | 極高導熱性,需處理裸片級高熱通量 | 隨溫度循環易產生泵出效應 ,導致空洞與失效 |
| 均熱片 (無氧銅) | ~400 | 極佳熱傳導與熱擴散能力 | 增加整體封裝體積、重量與熱傳遞路徑長度 |
| TIM2 (導熱膏、相變材料) | 2 - 7 | 低導熱性,提供表面貼合與機械緩衝 | 整體架構中熱阻最高的一環,常佔據總熱阻的 70% 以上 |
| 水冷板 (金屬) | 200 - 400 | 具備宏觀水道,與液體進行對流熱交換 | 流體對流邊界層限制了最終熱交換效率 |
此架構的核心瓶頸在於 TIM2 的存在:高階 TIM2 的熱傳導率通常僅約 2 至 7 W/m·K,與金屬銅約 400 W/m·K 的導熱能力相比,仍存在近百倍差距。 當 TIM2 厚度達數十微米時,其熱阻貢獻通常落在 0.1 至 1.0 °C·cm²/W。於過去晶片 TDP 僅數百瓦的時代,這樣的熱阻水準尚可接受;然而隨著 AI 晶片局部熱通量大幅提升,即使 TIM2 熱阻僅為 0.1 °C·cm²/W,仍可能在介面產生高達 100°C 的極端溫差,進一步推升晶片結溫,使其輕易突破 80°C 至 100°C 的安全運作區間,最終導致系統降頻、失效甚至崩潰。
因此,無論是傳統 Cold Plate 直接液冷架構,抑或 MCCP,本質上皆面臨相同的物理限制,也就是熱傳遞路徑過長,且高度依賴低導熱率的 TIM2 作為關鍵換熱介面。 MCCP 雖透過微縮冷板流道與提升對流換熱效率改善整體散熱表現,但仍無法繞過 TIM2 所形成的主要熱阻瓶頸。只要此介面層仍然存在,系統便難以實質突破高功率 AI 晶片的散熱限制,而這也正是業界進一步發展 MCL 架構的根本原因。
MCL 一體化架構將大幅縮短熱傳導路徑
| 層級(由上至下) | Cold Plate DLC | MCCP | MCL |
|---|---|---|---|
| 冷卻液循環層 | Cold Plate(一般通道 ~150 μm) | Cold Plate(微通道 80–100 μm) | 消除 |
| TIM 2 | 存在 | 存在 | 消除 |
| Heat Spreader | 存在 | 存在 | 消除 |
| 換熱核心 | Cold Plate 獨立於封裝外 | Cold Plate 獨立於封裝外 | Micro-channel Lid 整合換熱 |
| TIM 1 | 存在 | 存在 | 仍存在 |
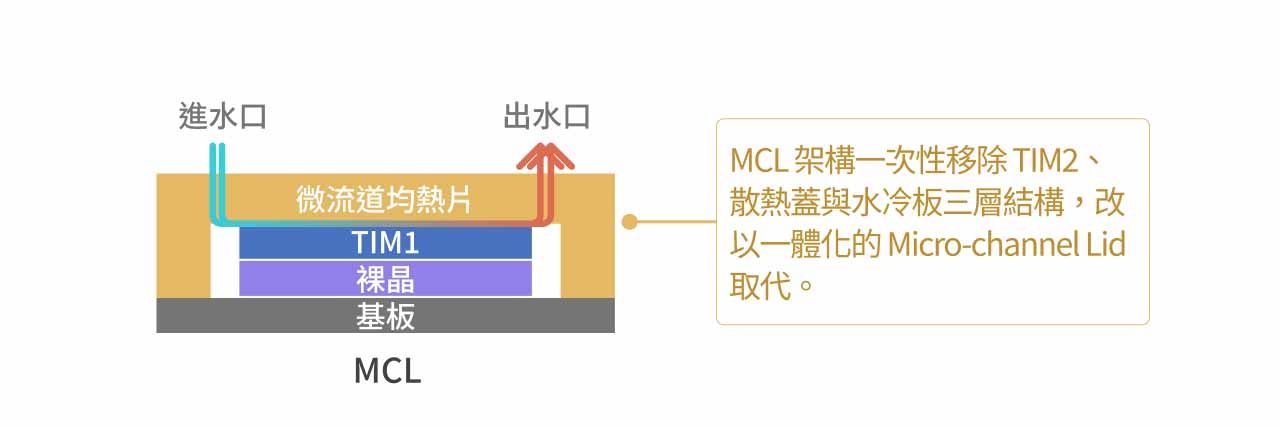
MCL 架構透過一次性移除 TIM2、Heat Spreader 與 Cold Plate 三層結構,改以一體化的 Micro-channel Lid 取代,使冷卻液可直接於最接近晶片的 Lid 內部循環,藉由顯著縮短熱傳導路徑以大幅降低整體熱阻。 此設計將原本分離的均熱片與冷水板功能整合為單一元件,即 Micro-channel Lid(微流道均熱片)。由於該結構本身即內建冷卻流道,可完全消除傳統架構中 TIM2 所形成的關鍵熱阻瓶頸,因而被視為未來 AI 伺服器突破高功耗散熱限制的重要技術方向。
MCL 散熱路徑解析(由下至上):
- 晶片發熱(SoC & HBM)。
- 熱量傳導至第一層散熱介面材料 TIM 1。
- 熱量直接進入 Microchannel Lid,冷卻液直接在緊貼著 TIM 1 的微小流道中循環,迅速帶走熱量。
就目前學術文獻而言,Lid-integral 微通道冷卻模組已具備具體實測數據可供參考。傳統微通道冷板,也就是 MCCP 類型,其熱阻大致落在 0.07 K/W 等級,實測結果顯示,相較於一般宏觀通道冷板,微通道冷板可提升約 50% 的散熱效能。至於 MCL,由於進一步移除 TIM 2 與 Heat Spreader,理論上相較於傳統 Cold Plate 直接液冷架構,最高可帶來約 3 倍的散熱效能提升,從而更有機會支撐 2.3 kW 以上 AI 晶片的高功耗散熱需求。
| 指標 | 數據 | 來源 |
|---|---|---|
| 晶片到冷卻液入口的熱阻 | 27.1 mm²·K/W | ScienceDirect,Lid-integral 微通道模組實測(流量 1 L/min) |
| 晶片表面最大溫差 | 6.3°C(實測)/ 4.1°C(模擬優化後) | 同上,熱通量 150 W/cm² 條件下 |
| 壓降 | 18.3 kPa(流量 1 L/min) | 同上 |
| 微通道尺寸 | 通道深度 250 μm、寬度約 210 μm | 同上 |
均熱片技術延伸價值浮現,成為 MCL 量產關鍵門檻
MCL 雖在硬體架構上移除了傳統均熱片,但這並不代表均熱與保護功能自此消失,反而是將兩者全面整合至 Micro-channel Lid 本體之中,並使其成為設計上最隱性、也最難突破的核心技術門檻。在傳統冷板架構下,均熱片表面上僅是一層金屬蓋板,實際上卻同時肩負保護脆弱裸晶與均勻擴散熱點兩項關鍵任務。其一方面作為矽晶結構抵禦封裝機械應力與反覆熱脹冷縮的第一道防線,另一方面則憑藉高導熱特性,先行將 AI 運算過程中 SoC 與 HBM 所產生的局部極端熱點加以擴散,避免熱量在未經均熱處理下直接衝擊換熱介面,進而削弱整體冷卻效率。
當 MCL 將封裝蓋板與換熱器整合為單一結構後,工程師必須在一片極薄的金屬基材上,同時平衡多項高度衝突的設計要求。該基材不僅需具備足夠的熱擴散能力,以避免局部過熱,亦必須在內部精準加工出 80 至 100 微米等級的微流道,以確保流量分布均勻並將壓降控制在可接受範圍內。 更具挑戰性的是,極細流道的導入不得削弱整體結構強度,仍須足以承受封裝製程中的外力負載,以及數萬次熱循環所累積的疲勞應力,而不產生變形或裂損。
此外,考量冷卻液長期流經微流道可能造成微粒沉積與堵塞風險,而 MCL 一旦受損,亦無法如傳統冷板般單獨拆換,往往意味著整顆高價 AI 晶片必須一併報廢,因此其長期可靠度驗證標準遠較傳統架構更為嚴苛。 為降低因流道大幅微縮所帶來的堵塞風險,系統過濾能力亦必須同步提升至 10µm 以下,方能支撐長期穩定運作。然而,若直接將 CDU 內部過濾器升級至此等級,又將進一步推升系統壓降、泵浦功耗與濾芯更換頻率,反映出液冷散熱架構朝 MCL 演進的同時,過濾系統升級亦已成為不可避免的配套方向。整體而言,上述任一設計條件若出現失衡,皆可能導致良率顯著下滑或產品失效,這也正是 MCL 開發週期遠較傳統冷板更長,且良率迄今仍為量產最大瓶頸的根本原因。
在此背景下,散熱產業中已發展多年的均熱片技術,於邁向 MCL 時代的過程中展現出新的延伸價值。長期深耕均熱片製造的廠商,憑藉在以下四項工程能力上的技術累積,正好具備切入 MCL 量產體系的重要基礎,並形成關鍵進入門檻:
- 金屬材料特性: 包含無氧銅的熱膨脹係數、反覆熱循環下的疲勞行為,以及與不同 TIM 的界面相容性。這些材料特性評估可直接應用於 MCL 的 Lid 基材選用與結構設計中,以降低流道結構在長期熱循環後因疲勞積累而失效的風險。
- 電鍍製程控制: 均熱片表面電鍍層需維持均勻、緻密及良好的基材結合力,以避免在熱循環中發生剝離。MCL 的微流道內壁同樣需要精密的電鍍處理來提升抗腐蝕性與導熱性,兩者在良率控制的邏輯上具備高度共通性。特別是在 Rubin 世代採用石墨/銦複合材料作為 TIM 2 後,因其對 Lid 表面具腐蝕性,電鍍層的品質控制更顯重要。
- 封裝結構力學: 均熱片在封裝過程中需承受來自基板翹曲、晶片壓合與固晶應力的多向力矩,廠商需對封裝件整體的力學行為有充分掌握。MCL 作為封裝結構的一環,亦面臨類似的挑戰,且因整合了流道設計而增加複雜度。隨著晶片尺寸放大,翹曲風險隨之提高,對封裝結構力學的標準也相應提升。
- 熱點擴散設計: 均熱片的設計重點在於如何在有限面積內將局部熱點均勻擴散。此設計邏輯同樣適用於 MCL,若 Lid 底部無法有效分散熱源,將會限制微流道的整體散熱效率。熱點擴散的設計經驗,構成了均熱片廠商在 MCL 開發上的技術基礎。
機會廠商
健策 (3653)
公司簡介
健策精密工業早期由精密模具與電子零件起家,現已聚焦高階散熱解決方案,核心產品包括高階均熱片、LED 導線架及車用 IGBT 散熱模組,並提供整合 CPU 扣件、均熱片與水冷板的一站式客製化散熱方案。 公司具備模具開發、沖壓及半導體級電鍍表面處理等垂直整合能力。
以 2025 年營收結構來看,散熱相關產品占比達 73%,為主要營收與獲利來源。 主要客戶涵蓋台積電、日月光投控、AMD、Intel 與 Nvidia 等全球晶圓代工、封測及晶片設計大廠,前幾大客戶合計營收占比逾 70%,水冷板產品亦已切入 Supermicro 等伺服器系統廠供應鏈。
競爭優勢:跨足封裝設計、精密製造與電鍍量產,健策具備切入 MCL 的先發基礎
在液冷技術持續升級的趨勢下,供應商必須同時具備機械加工與半導體封裝的跨領域能力。健策目前已切入 NVIDIA GPU 均熱片,以及台積電 CoWoS 封裝所需的 Lid 與 Stiffener 供應鏈,並累積了在晶片設計初期即參與幾何規格、材料選擇與介面定義的實務經驗。就 MCL 技術發展而言,健策憑藉其封裝設計能力、大規模電鍍量產基礎及與客戶長期合作關係,已具備一定競爭優勢。考量 MCL 量產對電鍍精度與封裝結構力學的要求更高,健策可望延伸其長期累積的精密沖壓能力,以因應微流道加工精度需求,並透過垂直整合電鍍產線強化良率控管,同時將既有 CoWoS 封裝經驗應用於解決更複雜的結構力學挑戰。
| MCL 關鍵製程門檻 | 健策對應能力 | 能力來源 |
|---|---|---|
| 微流道蝕刻精度 | 精密沖壓 + 長年製造均熱片薄壁結構 | 均熱片量產 30+ 年積累 |
| 電鍍製程良率 | 自有電鍍產線,熟悉銅基材電鍍層均勻性 | 垂直整合電鍍製程 |
| 封裝結構力學 | TSMC CoWoS Lid/Stiffener 核心供應商 | 封裝 Lid 長期合作 |
| 熱點均散設計 | 均熱片設計核心能力,直接移植至 MCL | 均熱片 R&D 積累 |
| 客戶設計早期參與 | NVIDIA GPU 每一世代均從設計初期參與 | 唯一供應商地位 |
成長動能 1 :Rubin 世代規格升級帶動 ASP 上行,並為健策 MCL 量產奠定技術基礎
MCL 預計要到 2027 年下半年至 2028 年才會開始帶來較明顯的營收貢獻。在此之前,2026 年下半年推出的 Rubin 世代可視為均熱片走向液冷整合的過渡階段,產品規格、製程難度與單價均明顯提升。由於 Rubin 採雙晶片設計,封裝尺寸放大,Stiffener 為避免熱循環下翹曲開裂,規格要求同步升級,單價預估將較過往提升。同時,因應新型 TIM2 材料特性,Lid 也升級為雙片式設計,並加入薄金電鍍保護製程,帶動單價較 Blackwell 世代進一步提升。Rubin 雙片鍍金 Lid 在電鍍精度、表面處理與結構設計上的要求,亦與未來 MCL 製造技術高度相關,相關量產經驗可望成為健策後續切入 MCL 的重要基礎。
| 時程 | 產品 | ASP 相對水準 | 確定性 |
|---|---|---|---|
| 現在 | B300 均熱片(石墨烯) | 基準(20–25 美元) | 量產中 |
| 2026 H2 | Rubin Stiffener + 雙片鍍金 Lid | 數倍(Stiffener 20–30 USD) | 3Q26 放量 |
| 2027 | CPO Stiffener(Spectrum-5 / Q5) | 30–60 美元/組 | 設計確認 |
| 2H27–2028 | 微流道均熱片(MCL) | 現行方案 7–10× | 設計待定案 |
成長動能 2 :健策同步跨足 CPO 與車用散熱成為中長期成長動能
除了 AI 業務外,健策亦將封裝件結構強化設計能力延伸至 CPO 領域,並有望成為 NVIDIA Spectrum-5 與 Quantum-5 交換晶片 Stiffener 的主要供應商。該業務預期可於 2027 年貢獻約 10% 的新營收占比,反映公司技術能力已可同步切入運算與網通兩大市場。另一方面,非 AI 業務中約占營收 16% 的 IGBT 散熱模組,則受惠於全球電動車滲透率提升,持續提供相對穩定且獨立於 AI 產業週期之外的營收來源。
元鈦科 (7892)
公司簡介
元鈦科技成立於 2022 年,專注於液冷設備與系統整合解決方案,核心產品包括 CDU、Sidecar 及客製化 SI 案場服務,主要聚焦資料中心與機房二次側系統建置。 公司增資後股本為 4.69 億元,並於 2026 年 1 月 16 日以 238 元登錄興櫃。主要客戶包括鴻海旗下鴻佰、緯創、緯穎,亦服務瑞昱、慧榮及創意等 IC 設計公司之實驗室與機房建置需求。
競爭優勢 1 :提前布局 CDU 與 Sidecar,相較同業具成本優勢及新產品開發能力
元鈦科的競爭優勢在於,其產品布局正位於液冷系統由過渡方案邁向完整水對水架構的核心位置。 隨著伺服器機櫃熱功率持續提升,液冷架構已由風扇背門與 Sidecar 等水對氣方案,逐步升級至以 CDU 為核心的水對水系統;而在直接液冷與 MCL 技術持續滲透下,晶片端導熱效率雖明顯提升,卻也同步拉高系統端對冷卻液循環、熱交換效率與整體穩定性的要求。元鈦科憑藉 Sidecar 與 CDU 的產品布局,成功掌握此一系統級散熱升級趨勢,成為液冷供應鏈中具關鍵地位的設備供應商。另一方面,CDU 為液冷系統中價值最高的核心設備之一,單價可達 5 至 15 萬美元,且隨設備功率由 600kW、1.3MW 升級至 2.5MW,並進一步朝 4MW 發展,帶動產品售價與技術門檻同步提升,形成量價齊揚的成長結構。相較國際同業,元鈦科具備約 15% 至 20% 的成本優勢,有助於其在市場擴張過程中強化價格競爭力與市占率;同時,公司亦積極投入負壓式 CDU 等新產品開發,進一步鞏固未來 3 至 5 年的成長潛力。
競爭優勢 2 :兼具設備製造與系統整合能力,以一站式方案提升專案價值與客戶黏著度
| 上游 | 中游 | 下游 |
|---|---|---|
| 土地、基礎設施等供應商 | 資料中心設計 & 建置規劃機房、機櫃產品、資訊安全、設施管理等 元鈦 (7892.TW) | 電腦機房、資料中心、伺服器代工及品牌廠等 |
元鈦科另一個競爭優勢在於其兼具設備製造與資料中心系統整合能力,並非僅是單純的設備供應商。此一商業模式使公司得以由單一產品銷售,進一步延伸至整體機房規劃與建置,提升單一客戶專案的整體價值。 當元鈦科承接資料中心建置案時,除可認列工程收入外,亦可同步帶動 CDU 與 Sidecar 等液冷設備銷售,形成設備與工程綁定的一站式解決方案,進一步放大營收規模與客戶黏著度。
此外,隨著散熱技術由系統級液冷進一步走向封裝級 MCL,液體流動、壓力控制、熱交換效率、漏液風險與系統穩定性的重要性持續提升,市場需求也將更傾向具備整體解決方案能力的供應商。元鈦科除提供 CDU 設備外,亦具備資料中心二次側系統整合能力,可涵蓋設備、管線與整體機房規劃。隨著 MCL 導入推升系統複雜度,元鈦科一體化整合能力的重要性可望進一步提升。
成長動能 1 :MCL 推動過濾系統升級,元鈦科外掛式過濾裝置將成為未來水流通道微縮趨勢
隨著 MCL 將水流通道大幅微縮至約 80µm,雖可顯著提升散熱效率,但也同步提高堵塞風險。 若雜質隨時間累積,將導致有效散熱面積縮小、冷卻效率下降,並使晶片表面溫度分布惡化,進一步影響運作效能與使用壽命。目前市面上資料中心 CDU 內建過濾系統多以 50µm 為標準,即使升級選配通常也僅達 25µm,仍難以滿足 MCL 所需的過濾等級。為保護 80µm 微流道並降低長期堵塞風險,過濾系統能力必須提升至 10µm 以下。元鈦科則掌握此一關鍵技術,推出可將冷卻液雜質過濾至 10µm 的外掛式過濾機台,在兼顧壓降與成本控制下,有效降低雜質累積風險,並延長整體水冷系統壽命。
