併購動機
推論時代的競爭壓力:NVIDIA 如何應對 ASIC 挑戰
NVIDIA 的營收結構目前仍高度仰賴 GPU 出貨量的成長。過去市場在模型訓練與推論兩個階段皆普遍依賴 NVIDIA GPU,使公司得以在 AI 浪潮下快速擴張。然而,近期市場觀點部分轉向,認為隨著 AI 產業從高速建設期邁向成熟應用期,訓練需求的增速可能會相對前期放緩。相較之下,若要支撐 AI 的大規模商業化,推論端的算力需求有機會成為下一階段的主要成長動能。因此,GPU 的通用性與 ASIC 的效率優勢將在推論市場形成直接的競合關係,並可能影響 NVIDIA 未來的營收動能與市場份額。
以 Google TPU 為例,為了兼容各類通用運算,GPU 內部保留大量對 AI 矩陣運算非必要的電路邏輯,導致面積浪費與漏電流上升,推升單位成本;相較之下,TPU 為為推論設計的 ASIC 晶片,能在硬體層級剔除 AI 無關電路,並以脈動陣列(systolic array)針對矩陣乘法優化,降低記憶體存取需求、提升運算密度。其次,在能耗層面,電網供給吃緊使 GPU 每瓦效能的邊際收益遞減,散熱與供電成本已佔總持有成本(TCO)30% 以上,而 TPU 由於結構更簡化且專用,其每瓦效能可較傳統 GPU 提升 2–3 倍,在相同電力配額下更能緩解資料中心的電力瓶頸。最後,大模型訓練需要數萬顆 GPU 協同,NVIDIA 倚賴的 NVLink 與乙太網路在超大規模下容易出現功耗損失放大、延遲不可控等問題,Google 則為 TPU 研發 OCS(光學電路交換),以光纖在硬體層級互連,降低對傳統交換機的依賴,讓叢集擴張至 10 萬顆晶片等級時仍能維持低延遲與高吞吐。此外,Google 在模型(Gemini)/ 框架(JAX、XLA)/ 編譯器 / 網路拓撲 / 資料中心調度等層面高度自控,重質整合度高,而 Meta、Anthropic 等廠商的採購,也反映大型科技公司在推論端已開始認可非 NVIDIA 的替代解法,對 NVIDIA 的長期護城河形成潛在壓力。在此背景下,NVIDIA 更需要在推論時代證明自身產品與生態的不可替代性,以延續其領先地位。
脈動陣列(Systolic Array) 脈動陣列是一種晶片設計方式,讓大量的小型運算單元像流水線一樣協作,快速且省電地完成矩陣運算(AI 最需要的運算)。 GPU 在原始設計上為了保留彈性,讓使用性涵蓋範圍從原本的圖形渲染、光線追蹤到 AI 科學計算,因此 GPU 在設計上並非以固定化「流水線」形式的計算作為主體。反之,ASIC 在高度客製化下,可以藉由脈動陣列的設計來優化計算效率,進而提升推論效率。
LPU 在推論市場的優勢
| LPU (Groq) | GPU (Nvidia) | TPU (Google) | |
|---|---|---|---|
| 主要功能 | AI 推理 (特別是LLM) | 通用並行運算訓練 & 推理 | AI / ML 加速訓練 & 推理 |
| 核心架構 | 確定性執行核心可程式化流程 | CUDA 核心 + Tensor Core | 矩陣乘法單元(MXU) |
Groq 成立於 2016 年,創辦人 Jonathan Ross 曾任 Google 晶片團隊高管,亦是早期 TPU 的核心參與者之一。Groq 堅持的並非 GPU 式通用並行路線,而是一套強調低延遲、可預測執行與極致推論效率的架構,此理念與 TPU 設計思路高度同源,但與 NVIDIA 傳統 GPU 取向存在明顯差異。Groq 團隊推出不同於 NVIDIA GPU 與 Google TPU 的晶片產品 LPU(Language Processing Unit),顧名思義針對 LLM 推論進行硬體層級優化與解構 (disaggregate)。
傳統的晶片架構包含許多獨立運作的核心 (core),每個核心都包含自己的運算、記憶體和指令控制單元,而這種結構在傳輸數據時,需要在核心之間反覆跳轉,導致路徑複雜且延遲不可預測。Groq 將功能解構,它將晶片橫向分為不同的功能區域,例如專門存數據的區域、專門做向量運算的區域等,而數據則在這些區域間流動,因此 LPU 可以進行更快的資料處理。LPU 的核心精神是簡化硬體,並用強大的編譯器安排來推進運算,拋棄了所有硬體控制邏輯,沒有分枝預測、沒有緩存管理、沒有仲裁器 ,硬體只專注於執行指令,使絕大部分電晶體都用於算術運算。
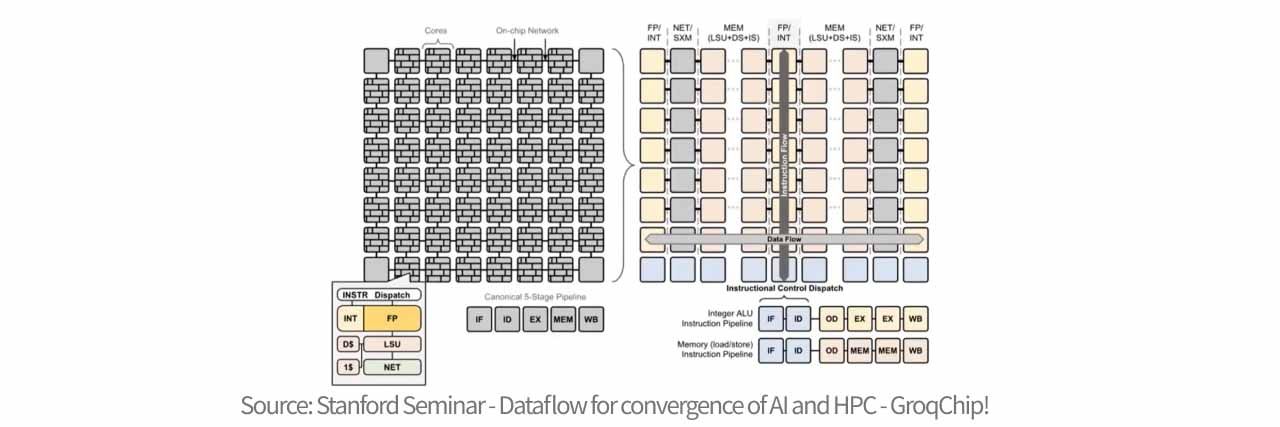
Groq 的 LPU 之所以能在反應速度上徹底超越傳統晶片,核心在於其確定性 (deterministic latency) 的架構。不同於傳統 GPU 依賴複雜的硬體調度器、分支預測與多層快取(Cache),這些機制雖然通用,卻會產生不可預知的延遲與硬體開銷;LPU 將控制權完全移交給編譯器,在執行前就精確排定了每一納秒的數據流向與運算時機。硬體上,它捨棄了延遲性較大的外部 DRAM,採用 SRAM(靜態隨機存取記憶體),其硬體組成採取了高度切片化與分散式的設計,其核心由 88 個獨立的記憶體切片(MEM slices)組成,每個切片擁有 8192 個地址,總容量達 230MB。這些切片被組織成四組計時群組(Quad timing groups),佈局於晶片的異構功能切片之間,與 MXM(矩陣運算)和 VXM(向量運算)單元緊密耦合。在運作上,每個週期能從兩個銀行(Banks)同時讀寫一個物理流,單次讀取即可產生 320Byte 的寬流數據。這種架構透過 串流寄存器(Stream Registers) 在南北向上對接完整 64 條流的頻寬,實現高達 80TB/s 的極限介面頻寬,讓數據能以完全確定的節奏在晶片內部高速流動,流經運算單元的瞬間即完成處理,完全不需要在內存間反覆搬運,消除了存取等待時間,這種設計讓 LPU 消除了所有隨機抖動與通訊冗餘,從而實現了極致的低延遲與超高速推理。
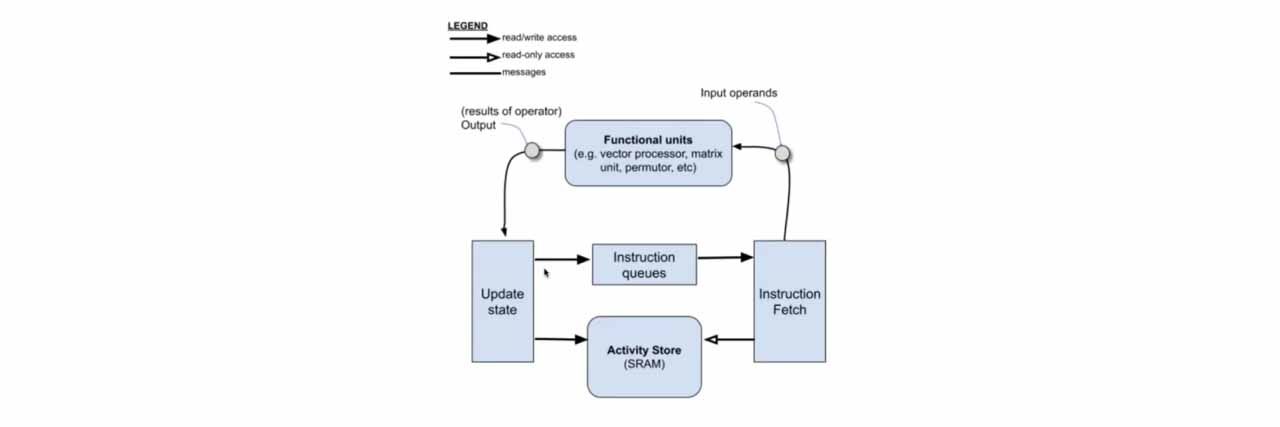
Groq 對外宣稱,其基於 LPU 的雲端服務在 Llama2 或 Mistral 等模型的推論與回應速度上,顯著優於以 NVIDIA AI GPU 為基礎的方案,並指出其輸出速度可達每秒約 500 tokens。相較之下,當時對標的 ChatGPT-3.5 公開版本約每秒 40 tokens,意味 LPU 在推論吞吐上可達 GPU 的 10 倍等級。在能耗方面,NVIDIA GPU 生成 tokens 可能需要約 10–30 焦耳,而 Groq LPU 僅約 1–3 焦耳,代表在推論速度提升的同時,單位能耗成本具數量級下降的可能。此外,NVIDIA GPU 依賴外部 HBM(高頻寬記憶體),資料在晶片與記憶體間搬運容易形成 memory wall 造成延遲,且 HBM 供給緊張亦是現實瓶頸,相對地,Groq 將大量 SRAM 直接整合於晶片上,雖容量較小但可提供極高頻寬(80TB/s、顯著高於 HBM 8TB/s),使其在文字生成等推論工作負載上有機會達到每秒 300–500 tokens 的效率優勢。
併購綜效&機會

隨著 AI 訓練 (traning) 已進入蓬勃發展的階段,AI 產業下一個重點領域將專注於推論 (inference) 領域,透過取得 Groq 技術,NVIDIA 可更快將 LPU 架構納入自身 AI 生態,形成 GPU(訓練)+ LPU(推論)的場景覆蓋。另一方面,NVIDIA 目前在供應鏈端透過掌握台積電 CoWoS 封裝與韓國大廠 HBM 產能,對 TPU 等競品形成先天供給壓制,反觀 Groq 的 LPU 因採用的是 14 奈米製程、不需依賴 HBM,因此技術上也不須採用 CoWoS 等高階製程,高度避開與 NVIDIA 大算力晶片的產能競爭,反而能利用較成熟產能加速出貨、搶佔推論市場窗口期,若 Groq 被其他潛在買家(如 Google、Meta)收編,將會對 NVIDIA 形成不小的風險。在此情況下,2025 年 12 月 24 日,NVIDIA 以 200 億美元取得 Groq 核心 AI 推論技術的非排他性授權,在業務切割上,NVIDIA 取得 Groq 核心資產與技術授權,但 GroqCloud 雲端業務不在交易範圍內並維持獨立運作;在人才吸納上,Groq 創辦人 Jonathan Ross、總裁 Sunny Madra 與多名核心成員加入 NVIDIA,以推進推論技術規模化落地;在公司獨立性上,Groq 仍作為獨立公司存在,由原 CFO Simon Edwards 出任新任 CEO 繼續維持公司營運。Groq 於最新一輪的投後估值已來到 69 億美元,後續可行性除 IPO 外,被大型雲端服務商或半導體業者以併購/策略投資方式納入生態系也是選項之一。NVIDIA 本次以技術授權方式與 Groq 達成合作,並延攬其核心管理與技術團隊加入,也再度顯示 NVIDIA 以推論作為下一個主戰場的決心。
- NVIDIA 在訓練與複雜推理上的產品優勢明確,但未來的 AI 應用(如 AI 醫生、自動駕駛、即時翻譯)核心需求是極低延遲與可預期的回應時間,而這塊市場過去 NVIDIA 的覆蓋相對薄弱。整合 Groq 後,NVIDIA 等同直接補齊低延遲推論產品組合,尤其 Groq 的 LPU 在 Batch Size = 1(單人即時互動)的工作負載下能跑出極高的 token throughput 與確定性延遲。若 NVIDIA 能吸收並整合 Groq 的 SRAM 存取與資料路徑設計思路,未來有機會在同一平台上同時兼具 GPU 的泛用性與 LPU 的反應速度,並徹底解決目前 HBM 記憶體帶來的 Memory Wall 問題。
- Groq 於 2025 年 9 月完成第 9 輪融資,募資規模達 7.5 億美元。NVIDIA 隨即快速敲定此一策略性合作案,反映其對該交易長期價值的高度認同。Groq 所強調的「確定性(deterministic)、低延遲」推論能力,正好補足 GPU 在即時推論場景中相對較弱的結構性短板。透過納入這項能力,NVIDIA 在面對雲端業者與企業客戶的採購決策時,得以降低因延遲或效率劣勢而流失訂單的風險,進而穩住出貨量(units),並延緩 ASP 下修壓力。
- 過去 NVIDIA 的 GPU 推論方案高度綁定 HBM 與 CoWoS,在推論占比快速上升的情境下,會同步放大 BOM 成本、供應鏈瓶頸及缺料風險。結合 Groq 架構至現有的 GPU 後,若能克服目前 LPU 高成本的困境,則 NVIDIA 在部分推論場景將有機會不再完全依賴「GPU + 大量 HBM」的重型配置,轉而提供更輕量、低成本、低延遲與能效為優先的推論方案,這等同於在推論端降低單位成本與交付風險,並使產品組合更貼近推論時代的主流需求。
併購風險
財務風險
NVIDIA 本次交易對價為 200 億美元,全現金支付。從資產負債表觀察,截至 3Q25 公司帳上現金及約當現金約 606 億美元,即使一次性支付 200 億美元,仍可保有逾 400 億美元的現金水位,足以支應日常營運周轉,同時維持對研發投入、股票回購與後續中型併購的財務彈性。
以現金流量體質做觀察,3Q25 NVIDIA 單季自由現金流達 221 億美元,營運現金流更高達 238 億美元,等同於公司僅需約一季的營運現金創造能力,即可覆蓋整筆交易對價,顯示本案在資金來源上不構成壓力。
從槓桿與償債能力角度,NVIDIA 長期 D/E 約落在 0.1、財務槓桿保守,利息保障倍數亦高達 400 倍以上,顯示公司具備極強的償債與利息負擔承受能力。全案以現金支付也顯示 NVIDIA 對於自身財務健康度的高度信心。綜合以上,本次交易的重心或許不在於對收購方是否帶來財務風險,而在於以投資回報的角度而言,此次的交易案是否能在合理的時間內轉化為可量化的營收貢獻,或快速提升自身產品的競爭力,穩住市場滲透率。
技術風險
- Groq 的 TSP/LPU 架構能否無縫納入 NVIDIA 既有推論軟體棧與開發者生態仍具不確定性。若無法被 CUDA 等體系完整吸收,那 Groq 對 NVIDIA 的定位將更偏向技術備援工具,而非可規模化產品。
- Groq 納入後,在低延遲推論可能直接與 NVIDIA 既有 GPU 推論方案形成內部競爭,若公司無法清楚劃分產品定位與客群邊界,可能出現產品內部競爭問題。
- 本次交易為非排他性,意味 Groq 技術理論上仍可能授權給其他對手或雲端客戶自建方案,NVIDIA 不一定是唯一、甚至不一定是最大受益者。
可行性分析
這類大規模併購交易往往容易引發監管部門介入與反壟斷審查。然而,本次 NVIDIA 採取的是「類併購」結構:交易核心並非將 Groq 完整併入公司體系,而是取得其關鍵推論技術的授權,並同步吸收 Groq 的核心團隊;同時,Groq 仍將維持獨立營運,其 GroqCloud 雲端業務亦不納入交易範圍,將持續獨立運作。
相較於過去 NVIDIA 嘗試併購 ARM 時,因涉及全球生態系關鍵 IP 而引發高度監管阻力,本次合作的授權形式更進一步採取「非獨家」安排,不僅降低外界對市場集中化的疑慮,也保留 Groq 作為獨立競爭者與技術供應者的空間,進而在策略布局與監管風險間取得更佳平衡。
Nvidia 代表性收購案
| 標的公司 | 收購金額 (美元) | 前後輪估值比值 | 收購主因 |
|---|---|---|---|
| Groq (2025) | 200 億 | ~ 190 % | 拓展推論領域競爭力 |
| Mellanox Technologies (2020) | 70 億 | ~ 17% | NVIDIA 史上最大正式完成的併購,奠定資料中心與網路技術基礎 |
| Run:ai (2024) | 7 億 | ~ 80% | 提供 GPU 池化與虛擬化技術,優化 AI 算力分配 |
| PortalPlayer (2006) | 3.57 億 | ~ 19% | 強化行動媒體播放器與手持裝置晶片技術 |
| (失敗) ARM 收購案 (2020-2022) | 400 億 | NA | 建立 AI 運算生態系 |
市場影響
主宰推論市場 ASIC 晶片受到威脅
LPU(語言處理單元)的技術核心在於其固定的設計架構,這與傳統 GPU 依賴硬體排程來處理不確定性的做法完全不同。LPU 的設計靈感源自數據流 (Dataflow) 概念,其內部完全取消了緩存 (Caches)、分枝預測與仲裁器 (Arbiters)。這種「拋棄複雜硬體控制邏輯」的作法,讓指令控制開銷降至 3% 以下,將絕大部分晶片面積留給了負責矩陣運算的 MXM 單元。
Groq 的編譯器在編譯階段就精確排程了數據在每一週期 (cycle) 的流向,這使得 LPU 能提供 100% 可預測且不隨時間抖動的低延遲表現。對於需要長文本生成與高頻連續推理的 AI 應用,LPU 透過 230MB 的片上 SRAM 提供高達 80 TB/s 的記憶體頻寬,遠超依賴外部記憶體的傳統架構,從而實現了每秒上千個 Token 的極致生成速度。若未來 Nvidia 將此一技術融入自家的 GPU,或是另外設計專門應用於推論的晶片,Nvidia 將能憑再訓練市場上既有的優勢及市占率,也將自家推論晶片打入市場,提升對 Broadcom (AVGO) 等傳統 ASIC 晶片商的競爭力。
LPU 影響 CoWos 及 HBM 的需求
LPU 採用的記憶體架構並未使用 HBM,因此現階段也不需要使用 CoWoS 先進封裝技術。傳統 GPU 與 AI ASIC 為了追求吞吐量,必須依賴昂貴且產能受限的 HBM 與 2.5D 封裝技術,然而 LPU 選擇將 230MB 的 SRAM 直接整合在晶片核心內部。這種設計對供應鏈的影響在於,LPU 證明了透過優化數據流路徑與軟體排程,可以在不依賴 HBM 的情況下達成更優異的推論效能。這對於目前的封裝巨頭來說,雖然短期內需求依然強勁,但長期而言,LPU 引導的 SRAM 使用架構可能分散對 CoWoS 產能的絕對依賴。
短期而言,這並非意味著 HBM 在市場上的地位會遭到取代。HBM 在多數的使用場景中仍具備強大的優勢,硬體規格來看單顆 GPU 的 HBM 容量是 LPU SRAM 的400 到 900 倍;而造價方面 SRAM 的成本也遠高於 HBM。若 NVIDIA 能在整體製程技術上有更進一步的突破,或許能將進一步提升 LPU 的適用場景。
LPU 的終端應用市場
LPU 的商業價值建立在其簡化硬體所帶來的低延遲。LPU 晶片內部與晶片之間不依賴傳統的異步網絡包交換,而是透過全域時間同步機制,由編譯器直接排程實體鏈路。這種技術讓 LPU 系統能像一個「巨型單一晶片」般運作,消除了數據傳輸中的延遲抖動(Jitter)。
在落地應用上,這種技術優勢直接轉化為即時性。在語音 AI 或虛擬老師等互動場景中,LPU 能提供極致的反應速度,解決了傳統架構產生的數位尷尬。而在對延遲極度敏感的金融高頻交易 (HFT),LPU 的確定性特性保證了推理時間的絕對穩定,不會因突發的數據擁塞而產生延遲變動。雖然其 SRAM 容量限制了單機承載的模型大小,但透過 Dragonfly 拓撲網路擴展技術,LPU 系統正逐步在需要「毫秒級反應」的專業領域中,建立起與 GPU 截然不同的市場版圖。
評論
針對 Nvidia 對 Groq 取得技術授權及延攬人才,在短期內可能並未有太大的綜效,原因在於目前 LPU 仍存在極大的缺點,例如其所使用的 SRAM 價格高昂,且記憶題容量極小,幾乎只有 HBM 的千分之一,因此在實際運用上仍有其限制性。
然 LPU 憑藉其快速的計算能力及節電效能,仍具有潛在技術優勢;另一方面,LPU 的設計本質上是簡化硬體並設計一套複雜的編譯器來負責運算,因此 Groq 的編譯器也具有潛在價值。除了技術的取得,人才延攬已為 AI 大戰的常態,加上 Nvidia 擁有龐大的自由現金流,因此以 200 億收購 Groq 並不會對其造成太大的負擔。因此針對 Nvidia 對 Groq 技術取得,需追蹤後續其將此技術結合至既有產品及業務的綜效。
